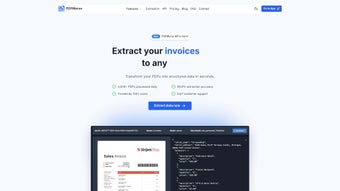
Wydajne narzędzie do ekstrakcji danych z PDF
PDFMerse to zaawansowane narzędzie oparte na sztucznej inteligencji, które umożliwia ekstrakcję danych z różnych formatów plików PDF i przekształcanie ich w uporządkowane informacje. Dzięki temu użytkownicy mogą łatwo przekształcić statyczne pliki PDF w dynamiczne dane, co znacząco usprawnia zarządzanie dokumentami. Narzędzie obsługuje różnorodne typy dokumentów, w tym faktury, dokumenty prawne oraz zapisy medyczne, co czyni je wszechstronnym rozwiązaniem w wielu kontekstach.
PDFMerse wyróżnia się zdolnością do ekstrakcji zarówno tekstów drukowanych, jak i odręcznych, co zwiększa jego użyteczność. Wbudowane procesy walidacji zapewniają dokładność i integralność wyodrębnionych danych, minimalizując błędy. Użytkownicy mogą opisać, co chcą wyodrębnić, a inteligentny model danych AI ułatwia ten proces. Narzędzie obsługuje dokumenty wielojęzyczne, a także oferuje API do łatwej integracji z systemami, zapewniając szybkie i efektywne procesy ekstrakcji.